Loading... <div class="tip share">请注意,本文编写于 1331 天前,最后修改于 1331 天前,其中某些信息可能已经过时。</div> ## 简介 protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。 Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。 你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。 Protobuf 是由 Google 开发的一种数据交换的序列化协议,性能非常高,大部分IM通讯协议都是使用它来传输,例如支付宝、微信、QQ等 ## 安装 从项目GitHub Releases下载需要的压缩包 例如我是在windows进行开发,所以下载protoc-3.14.0-win64.zip,其它操作系统见官方文档 解压后在protoc-3.14.0-win64\bin路径下有一个protoc.exe程序,为了方便我这边是放到了C:\Windows\System32目录下,也可以放任意目录 项目地址:https://github.com/protocolbuffers/protobuf/releases ## Java ProtoBuf Demo > 编写描述文件 ``` // 指定proto3语法,否则默认为proto2 syntax = "proto3"; package demo; // 指定包名 option java_package = "com.mikuac.demo"; // 指定类名 option java_outer_classname = "ProtoBufTest"; message SearchRequest { // 指定字段类型为string,标识号为 1 string query = 1; int32 page_number = 2; int32 result_per_page = 3; } ``` > 编译生成 Java 代码 Protobuf 编译器通过描述文件(.proto文件)生成对应于语言的代码,代码中定义了消息类型、获取、设置、编解码序列化等操作。这也是为什么 Protobuf 支持跨语言传输,因为消息所有端共用一个通用的描述文件 ``` protoc --java_out=. test.proto #在当前目录生成ProtoBufTest.java ``` ``` # 引入Maven依赖 <!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java --> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>4.0.0-rc-2</version> </dependency> ``` > SpringBoot Demo ```java @SpringBootApplication public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); System.out.println("----------开始构建模型----------"); ProtoBufTest.SearchRequest.Builder searchRequestBuilder = ProtoBufTest.SearchRequest.newBuilder(); searchRequestBuilder.setQuery("测试"); searchRequestBuilder.setPageNumber(10); searchRequestBuilder.setResultPerPage(1); ProtoBufTest.SearchRequest searchRequestData = searchRequestBuilder.build(); System.out.println(searchRequestData.toString()); System.out.println("----------模型构建结束----------"); System.out.println("\n----------开始序列化----------"); for (byte b : searchRequestData.toByteArray()) { System.out.print(b); } System.out.println("\n----------序列化完成----------"); System.out.println("\n" + "bytes长度" + searchRequestData.toByteString().size()); System.out.println("\n----------反序列化开始----------"); ProtoBufTest.SearchRequest sr = null; try { sr = ProtoBufTest.SearchRequest.parseFrom(searchRequestData.toByteArray()); } catch (InvalidProtocolBufferException e) { e.printStackTrace(); } System.out.println(sr); System.out.println("----------反序列化完成----------"); } } ``` ## 运行结果 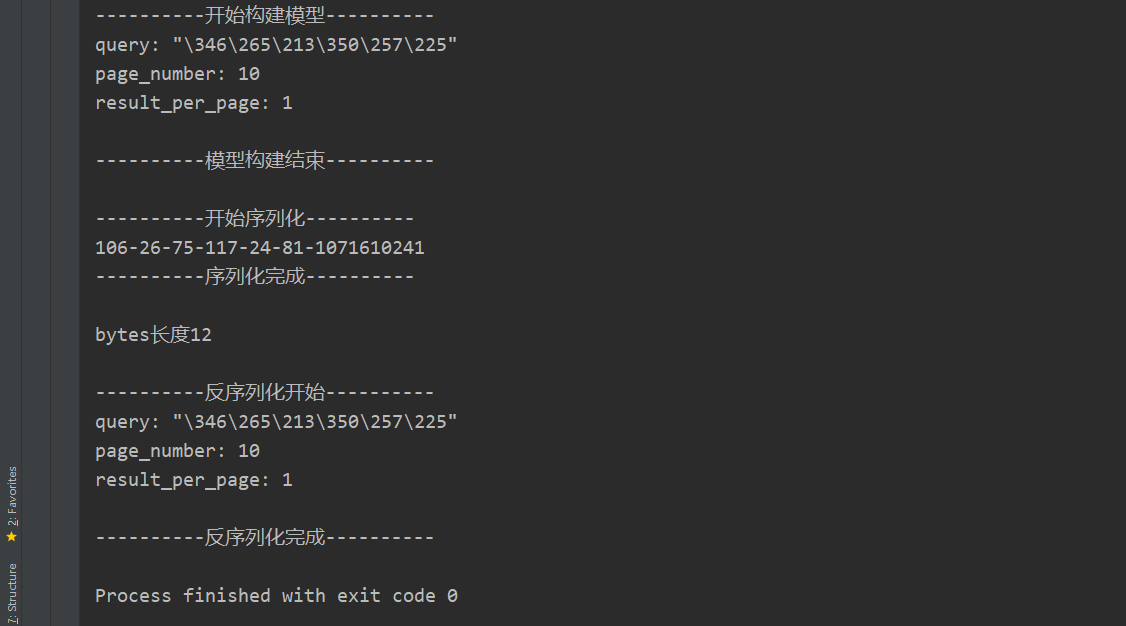 ## ProtoBuf2的三个关键字 required:表示该字段必须有值 optional:消息格式中该字段可以有0个或1个值(不超过1个) repeated:该字段可以重复任意次(包括0次),重复的值的顺序会被保留,表示该值可以重复,相当于java中的List ## ProtoBuf3移除required与optional 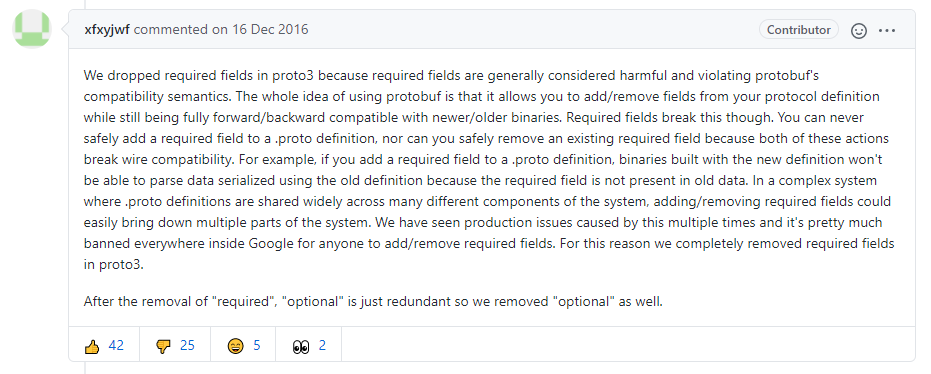 proto3仅支持repeated字段修饰,如果使用required,optional编译会报错 ## 分配标识号 每个字段都有唯一的数字标识号,需要注意的是 [1,15] 之内的标识在编码时只占用 1 字节,[16,2047] 之内的占用 2 字节,所以应该对那些频繁出现的消息元素预留 [1,15] 之内的标识号 ## 标量数值类型 一个标量消息字段可以含有一个如下的类型——该表格展示了定义于.proto文件中的类型,以及与之对应的、在自动生成的访问类中定义的类型 | .proto Type | Notes | C++ Type | Java Type | Python Type[2] | Go Type | Ruby Type | C# Type | PHP Type | | ----------- | -------------------------------------------------------------------------- | -------- | ---------- | -------------- | ------- | ------------------------------ | ---------- | -------------- | | double | | double | double | float | float64 | Float | double | float | | float | | float | float | float | float32 | Float | float | float | | int32 | 使用变长编码,对于负值的效率很低,如果你的域有可能有负值,请使用sint64替代 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer | | uint32 | 使用变长编码 | uint32 | int | int/long | uint32 | Fixnum 或者 Bignum(根据需要) | uint | integer | | uint64 | 使用变长编码 | uint64 | long | int/long | uint64 | Bignum | ulong | integer/string | | sint32 | 使用变长编码,这些编码在负值时比int32高效的多 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer | | sint64 | 使用变长编码,有符号的整型值。编码时比通常的int64高效。 | int64 | long | int/long | int64 | Bignum | long | integer/string | | fixed32 | 总是4个字节,如果数值总是比总是比228大的话,这个类型会比uint32高效。 | uint32 | int | int | uint32 | Fixnum 或者 Bignum(根据需要) | uint | integer | | fixed64 | 总是8个字节,如果数值总是比总是比256大的话,这个类型会比uint64高效。 | uint64 | long | int/long | uint64 | Bignum | ulong | integer/string | | sfixed32 | 总是4个字节 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer | | sfixed64 | 总是8个字节 | int64 | long | int/long | int64 | Bignum | long | integer/string | | bool | | bool | boolean | bool | bool | TrueClass/FalseClass | bool | boolean | | string | 一个字符串必须是UTF-8编码或者7-bit ASCII编码的文本。 | string | String | str/unicode | string | String (UTF-8) | string | string | | bytes | 可能包含任意顺序的字节数据。 | string | ByteString | str | []byte | String (ASCII-8BIT) | ByteString | string | ## 默认值 当一个消息被解析的时候,如果被编码的信息不包含一个特定的singular元素,被解析的对象锁对应的域被设置位一个默认值,对于不同类型指定如下: - 对于strings,默认是一个空string - 对于bytes,默认是一个空的bytes - 对于bools,默认是false - 对于数值类型,默认是0 - 对于枚举,默认是第一个定义的枚举值,必须为0; - 对于消息类型(message),域没有被设置,确切的消息是根据语言确定的,详见[generated code guide](https://developers.google.com/protocol-buffers/docs/reference/overview?hl=zh-cn "generated code guide") - 对于可重复域的默认值是空(通常情况下是对应语言中空列表) ## 从.proto描述文件生成了什么? 当用protocol buffer编译器来运行.proto文件时,编译器将生成所选择语言的代码,这些代码可以操作在.proto文件中定义的消息类型,包括获取、设置字段值,将消息序列化到一个输出流中,以及从一个输入流中解析消息。 - 对C++来说,编译器会为每个.proto文件生成一个.h文件和一个.cc文件,.proto文件中的每一个消息有一个对应的类。 - 对Java来说,编译器为每一个消息类型生成了一个.java文件,以及一个特殊的Builder类(该类是用来创建消息类接口的)。 - 对Python来说,有点不太一样——Python编译器为.proto文件中的每个消息类型生成一个含有静态描述符的模块,,该模块与一个元类(metaclass)在运行时(runtime)被用来创建所需的Python数据访问类。 - 对go来说,编译器会位每个消息类型生成了一个.pd.go文件。 - 对于Ruby来说,编译器会为每个消息类型生成了一个.rb文件。 - javaNano来说,编译器输出类似域java但是没有Builder类 - 对于Objective-C来说,编译器会为每个消息类型生成了一个pbobjc.h文件和pbobjcm文件,.proto文件中的每一个消息有一个对应的类。 - 对于C#来说,编译器会为每个消息类型生成了一个.cs文件,.proto文件中的每一个消息有一个对应的类。 最后修改:2020 年 12 月 04 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 0 如果觉得我的文章对你有用,请随意赞赏
